

1. FLUX
FLUX는 독일의 Black Forest Labs에서 개발한 텍스트-투-이미지(text-to-image) 생성 모델로, 자연어 프롬프트를 기반으로 고품질의 이미지를 생성하는 데 특화되어 있습니다. FLUX는 다양한 버전으로 제공되며, Schnell 버전은 Apache 2.0 라이선스로 공개되어 개인, 학술, 상업적 용도로 자유롭게 사용할 수 있습니다.
텍스트 표현과 정확한 손 표현이 강점이라고 알려져 있습니다. Stable Diffusion, Stable Diffusion XL 등과 비교하여 고품질의 이미지를 생성할 수 있지만, 고성능 GPU를 필요로 합니다. 일반적으로 FLUX를 구동하기 위해서 12GB이상의 VRAM이 장착된 Nvidia 그래픽 카드가 장착되어 있어야 합니다. 이미지를 생성하는 시간도 일반적인 Stable Diffusion에 비해 평균 2~3배, 혹은 5배까지도 차이가 날 수 있습니다.
FLUX 모델의 버전별 차이는 다음과 같습니다.
- FLUX.1 Schnell: 빠른 이미지 생성을 목표로 한 경량화 모델로, Hugging Face에서 다운로드 가능
- FLUX.1 Dev: 개발자 및 연구자를 위한 버전으로, 비상업적인 목적으로 사용 가능
- FLUX.1 Pro: 상업적 사용을 위한 고급 버전으로, API 형태로 제공되며 라이선스 계약이 필요
아직 Pro는 오픈소스로 풀리지 않았기 때문에, Dev와 Schnell을 사용 목적에 맞게 사용하시면 됩니다.
2. ComfyUI 설치
ComfyUI 설치 방법은 이전 [WAN Image to Video 설명글]에 자세하게 적혀 있습니다.
최신 버전의 Portable 버전을 다운로드 받아 설치하시면 됩니다.
3. 파일 준비
다양한 버전의 FLUX 모델들이 존재하고 있는데, 먼저 FLUX를 이용하기 위해서는 기본 모델 파일, CLIP 모델 파일, VAE 파일 등을 다운받아야 합니다. CLIP 및 VAE를 합친 체크포인트 모델도 존재하지만, 현재 일반적으로 오픈소스 커뮤니티에서 공유되고 있는 형태는 순수 모델 파일을 위주로 배포가 되고 있기 때문에, 모델 파일, CLIP 파일, VAE 파일을 각각 따로 다운로드 받는 것을 권장합니다.
3.1. FLUX 모델 파일
3.1.1. 고성능 GPU 사용 (16GB+ VRAM)
일반적으로 사용할 수 있는 버전은 Schnell 및 Dev 버전입니다. Dev가 Schnell에 비해 품질이 좀 더 좋지만, 더욱 고성능 GPU를 요구하며 상업적으로 사용이 불가합니다.
공식 UNET 모델 파일은 Schnell 버전은 [이곳]에서 다운로드 하시면 되며, Dev 버전은 [이곳]에서 다운로드 가능합니다.
(Dev 버전은 파일에 바로 액세스가 불가능하여 해당 링크로 진입 후 flux1-dev.safetensors 파일을 직접 다운로드 받으면 됩니다.)
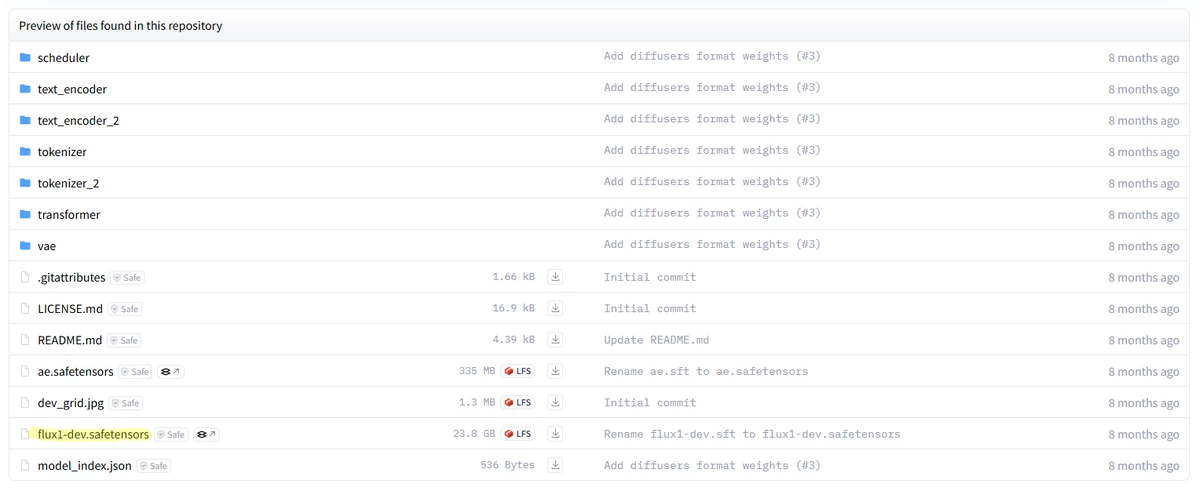
3.1.2. 그 외의 일반 성능 GPU
위 공식 모델 파일들은 16GB 이상의 VRAM이 장착된 고성능 GPU에서만 동작이 가능합니다.
따라서, 하이엔드 GPU를 사용하지 않고 있다면 경량화 버전의 모델을 사용해야 합니다. Civitai, 허깅페이스 등에서 다양한 FLUX 기반 병합 fp8 또는 양자화 모델(GGUF 플러그인 별도 필요)들이 배포 중입니다. fp16 기본 모델보다 이런 경량화 된 모델이나 양자화 모델을 사용하는것을 추천합니다.
ComfyUI에서 fp8 모델에 CLIP 및 VAE를 포함한 체크포인트 모델을 공유 중이긴 합니다. 하지만, 위에 설명한 바와 같이 AI 모델 공유 사이트에서 배포중인 여러 모델들은 CLIP이나 VAE가 포함되 않은 모델들이 많기 때문에 추천하지 않습니다.
다운로드 받은 모델 파일은 ComfyUI 설치된 폴더기준으로 ComfyUI/models/diffusion_models 폴더에 넣어줍니다.
3.2. CLIP 파일
CLIP 파일은 일단 두 가지가 필요합니다. t5xxl_fp16.safetensors 파일과 clip_l.safetensors 파일입니다.
두 파일 모두 [이곳] 에서 다운로드 가능합니다.
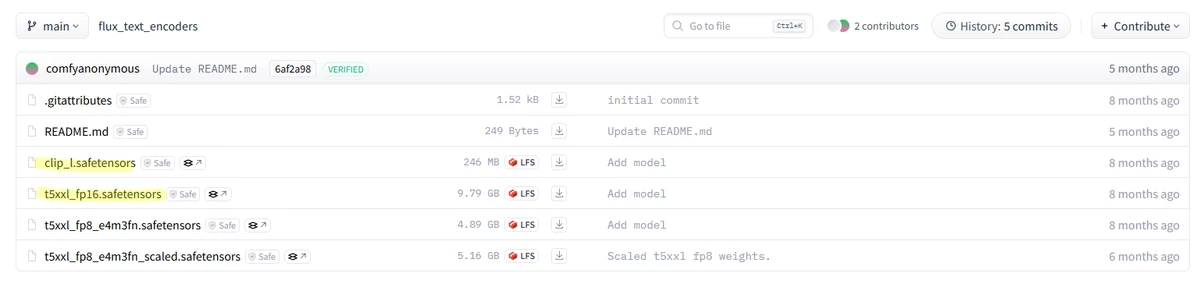
다운로드 받은 파일은 ComfyUI가 설치된 폴더기준으로 ComfyUI/models/text_encoders 폴더에 넣어줍니다.
PC에 설치된 메모리(VRAM + RAM)가 32GB 미만이라면, t5xxl_fp8_e4m3fn.safetensors 파일을 사용하시기 바랍니다.
3.3. VAE 파일
VAE파일도 공식 파일이 존재해서 [이곳]에서 다운로드 가능합니다.
ComfyUI 설치 폴더 기준, ComfyUI/models/vae 폴더에 넣어줍니다.
4. 사용하기
4.1. ComfyUI 실행
윈도우에서 명령프롬프트를 열고 ComfyUI 설치 폴더로 이동하여 에서 run_nvidia_gpu.bat 파일을 실행합니다.

4.2. Workflow 불러오기
FLUX를 이용해 Text to Image를 보다 편리하게 이용할 수 있도록 Workflow를 작성해 두었습니다. LoRA 및 Upscale 까지 이용이 가능하도록 구성되어 있으며, 기본 적으로 이 기능들은 Bypass (우회) 하도록 설정되어 있습니다. 원하시는 경우 우회를 해제하여 사용하실 수 있습니다.
Workflow 파일은 [이곳]에서 다운로드 가능합니다.
다운로드 받은 workflow 파일을 ComfyUI로 드래그 앤 드롭해줍니다.
4.3. 설정 및 생성하기
Workflow를 불러오면 다음과 같이 나타납니다.
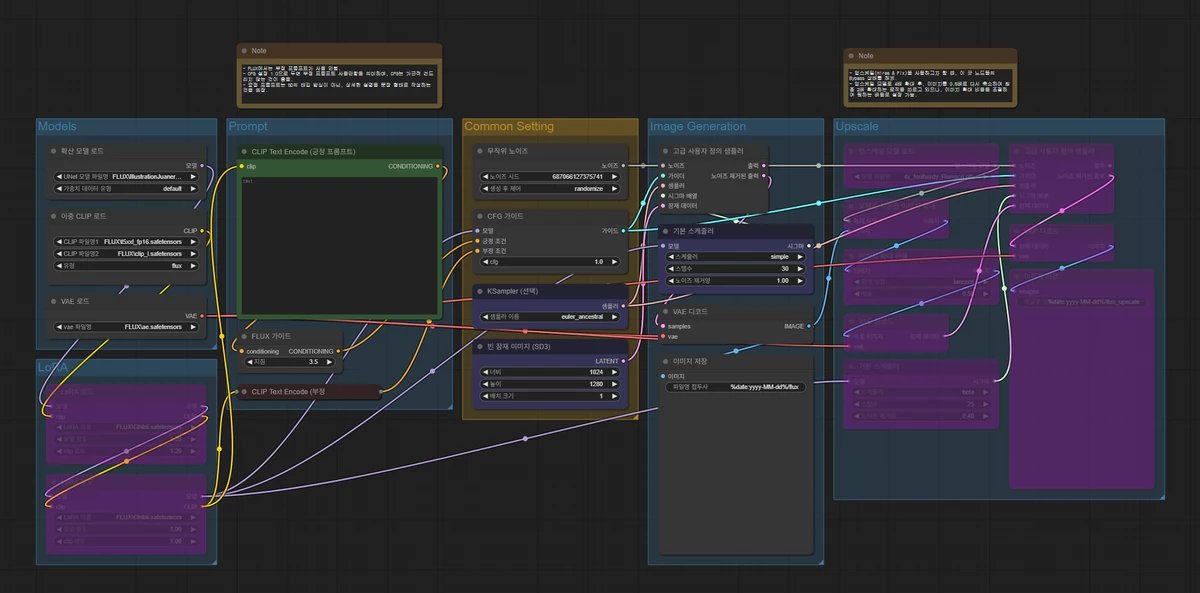
주요한 부분을 하나씩 살펴보면 다음과 같습니다.
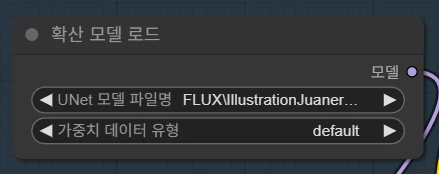
확산 모델 로드 노드에서 아까 다운로드 받은 UNET 모델을 지정해 줍니다.
CLIP 로드 노드에서도 다운로드 받은 CLIP파일들을 지정해 줍니다.
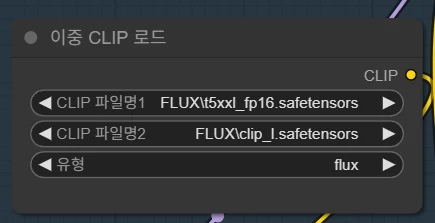
유형은 flux로 설정합니다.
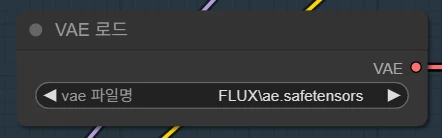
VAE 로드 모드에서도 마찬가지로 다운로드 받은 파일을 지정해 줍니다.
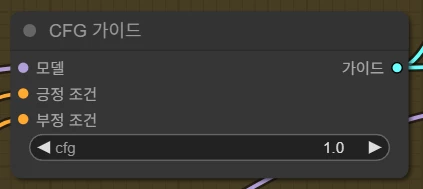
CFG는 1.0으로 설정해야 합니다. 이유는 후술할 예정입니다.
샘플러는 Stable Diffusion과 같이 선택이 가능합니다. FLUX의 경우 동작이 제대로 안되는 샘플러가 있기 때문에 보통, euler, euler a, unipc 등을 주로 사용하는 것으로 보입니다.
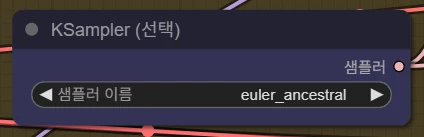
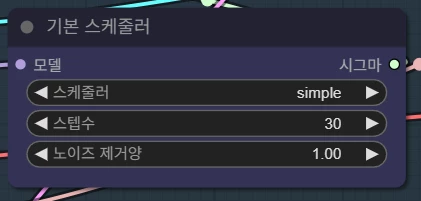
스케줄러는 샘플러에 맞게 사용합니다. normal, simple, beta 등을 샘플러에 맞게끔 주로 사용합니다. 스텝수는 20~40 사이로, UNET 모델에 맞게끔 사용하시면 됩니다.
이미지 크기는 SDXL과 유사하게 1024픽셀 이상으로 지정해줍니다. 하지만, 모델에 따라 약간의 권장 사이즈 차이는 있을 수 있습니다.

마지막으로, 생성할 이미지에 대한 프롬프트를 작성합니다.
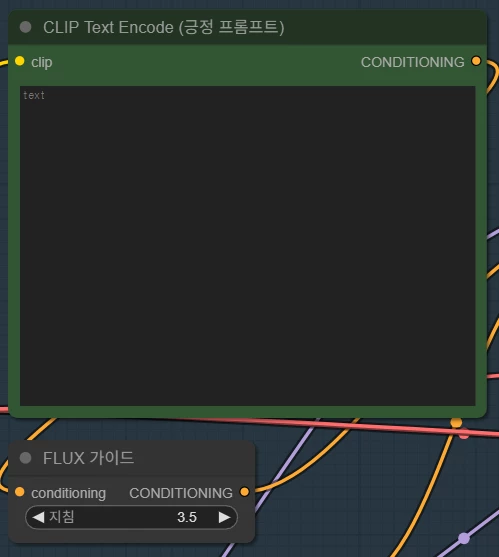
FLUX의 경우, 기존 Diffusion 모델과 달리 부정 프롬프트를 사용하지 않습니다. 위에서 CFG를 1.0으로 설정한 이유가 이 때문입니다.
또한 프롬프트의 경우 기존 SD모델과 달리 태깅 방식보다 문장 형태로 자세하게 기재하는 것이 좋습니다. 상세하게 묘사할 수록 더 좋은 결과를 얻을 수 있습니다.
태깅 방식으로도 생성은 가능하지만 의도하지 않은 결과가 나올 가능성이 높습니다.
이제 ComfyUI의 실행 버튼을 눌러 이미지를 생성할 수 있습니다.
다양한 FLUX모델을 이용하여 창의적인 이미지를 생성해 보시기 바랍니다.
아래는 요즘 유행하는 지브리풍 (GPT가 아닌 진짜 지브리 스튜디오 애니메이션 스타일)으로 생성한 일러스트레이션입니다.


지금까지 ComfyUI + FLUX Text to Image에 대한 글이었습니다.
끝까지 읽어주셔서 감사합니다.
🚫무단 펌을 금합니다.🚫
첨부파일 16
-
a7929fd3c27f89011226089c4e9310e8.webp
121.9KB
-
28872b00bd9f111fa6c73f32d88b4167.webp
38.4KB
-
57e584517f56c10e92541e42f512283d.webp
25.7KB
-
dec6f46605a62069e57be398f39e15de.webp
3.9KB
-
9cb6c186aa765f18cdb4c9b8a55a7f56.webp
16.8KB
-
3a4d7e1fc271dad625e4d5dd95b284d6.webp
61.8KB
-
b23c1c12b8e8280f3e80a755fcd7afcd.webp
7KB
-
1224c625b5a0e727526750b678f09067.webp
8.4KB
-
5edc1a61b2a34a64068576e6bbc0aaf1.webp
4.9KB
-
8e052c1ac6ba7c33eead02ea74f63d76.webp
5.3KB
-
150794c959063067dc5e6798dcf4d756.webp
6KB
-
4cae1e0fc682ead8325bc7931e7c448e.webp
7.7KB
-
202acd7c8375ec181f9e334c6543d3a2.webp
6.9KB
-
7dce69c9063bfb77a993466a0d0fcc7f.webp
14.8KB
-
13dca044e9427753826df05ae4a9a9e7.webp
94.3KB
-
4eb72c97a3bd649766d805ce59a2b4d0.webp
92.6KB
-
번호제목작성자날짜조회추천
- 게시글이 없습니다.